---
title: "Práctico 5. Visualización de variables en Quarto"
subtitle: "R data analisis"
linktitle: "Práctico 5: Visualización"
date: "2024-04-09"
lang: es
---
# Presentación
# Objetivo de la práctica
Esta práctica asume como base el desarrollo de la [Práctica anterior](https://r-data-analisis.netlify.app/practicos/04-content), a la cual se hará referencia permanente. Sin embargo, en esta oportunidad la base de datos contiene los datos de los 18 países participantes en la encuesta, no solo Chile. El código específico que crea esta base está disponible [acá](https://github.com/Kevin-carrasco/R-data-analisis/blob/main/practicos/latin_proc.R)
# Quarto documents
Como recordarán del primer práctico, un documento de Quarto comienza con el **yaml**, que sigue una estructura similar a esta:
----
title: "Mi Documento"
format:
html:
toc: true
number-sections: true
----
Luego, podemos escribir en el documento, separando por títulos (#) cada sección. La jerarquía de los títulos se establece según la cantidad de '#'.
A continuación, en esta guía combinaremos el paso-a-paso de crear un documento dinámico con quarto, a la vez que vamos viendo distintas funciones de este proceso.
Por ejemplo, como hacer una nota al pie[^1]. Para hacerlo, solo debemos escribir [ ^2] pero sin el espacio entre los corchetes. Luego, en otra línea escribimos [^2]: Esta es la nota al pie
[^1]: Esta es la nota al pie
# Código de análisis de ejemplo
Para poder escribir código de análisis en un documento Quarto debemos generar trozo de código llamado 'Chunk', que se puede crear con ctrl+alt+i o directamente en el menú de arriba en 'Code -> Insert Chunk'.
## Cargar paquetes
```{r}
pacman::p_load(sjlabelled,
dplyr, #Manipulacion de datos
stargazer, #Tablas
sjmisc, # Tablas
summarytools, # Tablas
kableExtra, #Tablas
sjPlot, #Tablas y gráficos
corrplot, # Correlaciones
sessioninfo, # Información de la sesión de trabajo
ggplot2) # Para la mayoría de los gráficos
```
## Cargar bases de datos
Cargamos ambas bases de datos desde internet
```{r}
load(url("https://github.com/Kevin-carrasco/R-data-analisis/raw/main/files/data/latinobarometro_total.RData")) #Cargar base de datos
load(url("https://github.com/Kevin-carrasco/R-data-analisis/raw/main/files/data/data_wvs.RData")) #Cargar base de datos
```
Para trabajar con ambas bases, agruparemos las variables de interés por país, por lo que ya no trabajaremos directamente con individuos.
```{r}
context_data <- wvs %>% group_by(B_COUNTRY) %>% # Agrupar por país
summarise(gdp = mean(GDPpercap1, na.rm = TRUE), # Promedio de GDP per capita
life_exp = mean(lifeexpect, na.rm = TRUE), # Promedio esperanza de vida
gini = mean(giniWB, na.rm = TRUE)) %>% # Promedio gini
rename(idenpa=B_COUNTRY) # Para poder vincular ambas bases, es necesario que la variable de identificación se llamen igual
context_data$idenpa <- as.numeric(context_data$idenpa) # Como era categórica, la dejamos numérica
proc_data <- proc_data %>% group_by(idenpa) %>% # agrupamos por país
summarise(promedio = mean(conf_inst, na.rm = TRUE)) # promedio de confianza en instituciones por país
```
## Unir bases de datos
Para vincular nuestras bases de datos existen múltiples opciones, la primera es 'merge' de R base y las siguientes tres vienen desde dplyr: 'right_join', 'full_join' y 'left_join'. Cada una tiene sus propias potencialidades y limitaciones y dependerá de cada caso cuál usemos
### Probemos merge
```{r}
data <- merge(proc_data, context_data, by="idenpa")
```
```{r}
data <- data %>%
mutate(idenpa = as.character(idenpa)) %>%
mutate(idenpa = case_when(
idenpa == "32" ~ "Argentina",
idenpa == "68" ~ "Bolivia",
idenpa == "76" ~ "Brasil",
idenpa == "152" ~ "Chile",
idenpa == "170" ~ "Colombia",
idenpa == "188" ~ "Costa Rica",
idenpa == "214" ~ "Cuba",
idenpa == "218" ~ "República Dominicana",
idenpa == "222" ~ "Ecuador",
idenpa == "320" ~ "El Salvador",
idenpa == "340" ~ "Guatemala",
idenpa == "484" ~ "Honduras",
idenpa == "558" ~ "México",
idenpa == "591" ~ "Nicaragua",
idenpa == "600" ~ "Panamá",
idenpa == "604" ~ "Paraguay",
idenpa == "858" ~ "Uruguay",
idenpa == "862" ~ "Venezuela"))
data$gdp <- as.numeric(data$gdp)
data$gdp[data$gdp==0] <- NA
data <- na.omit(data)
```
## Visualizaciones
Podemos establecer referencias cruzadas para las tablas y gráficos dentro del texto, para poder automatizarlo, como ejemplo así, pero dentro del chunk:
#| label: tbl-sjmisc
#| tbl-cap: "Descriptivos con sjmisc"
### Descriptivos
El Chunk se debería ver así:
#| label: tbl-sjmisc
#| tbl-cap: "Descriptivos con sjmisc"
sjmisc::descr(data,
show = c("label","range", "mean", "sd", "NA.prc", "n"))%>% # Selecciona estadísticos
kable(.,"markdown") # Esto es para que se vea bien en quarto
```{r}
#| label: tbl-sjmisc
#| tbl-cap: "Descriptivos con sjmisc"
sjmisc::descr(data,
show = c("label","range", "mean", "sd", "NA.prc", "n"))%>% # Selecciona estadísticos
kable(.,"markdown") # Esto es para que se vea bien en quarto
```
Luego de establecer el link y el nombre de la tabla, podemos referenciar acá con un @, así: @ tbl-sjmisc (pero junto), y que se vería así @tbl-sjmisc
### otra opción
```{r}
#| label: tbl-summarytools
#| tbl-cap: "Descriptivos con summarytools"
view(dfSummary(data, headings=FALSE))
```
La tabla @tbl-summarytools muestra los estadísticos descriptivos de la base de datos hecha con summarytools
### Gráficos
Y para los gráficos se hace de la misma forma:
#| label: fig-gdp
#| fig-cap: "Plots"
```{r}
#| label: fig-gdp
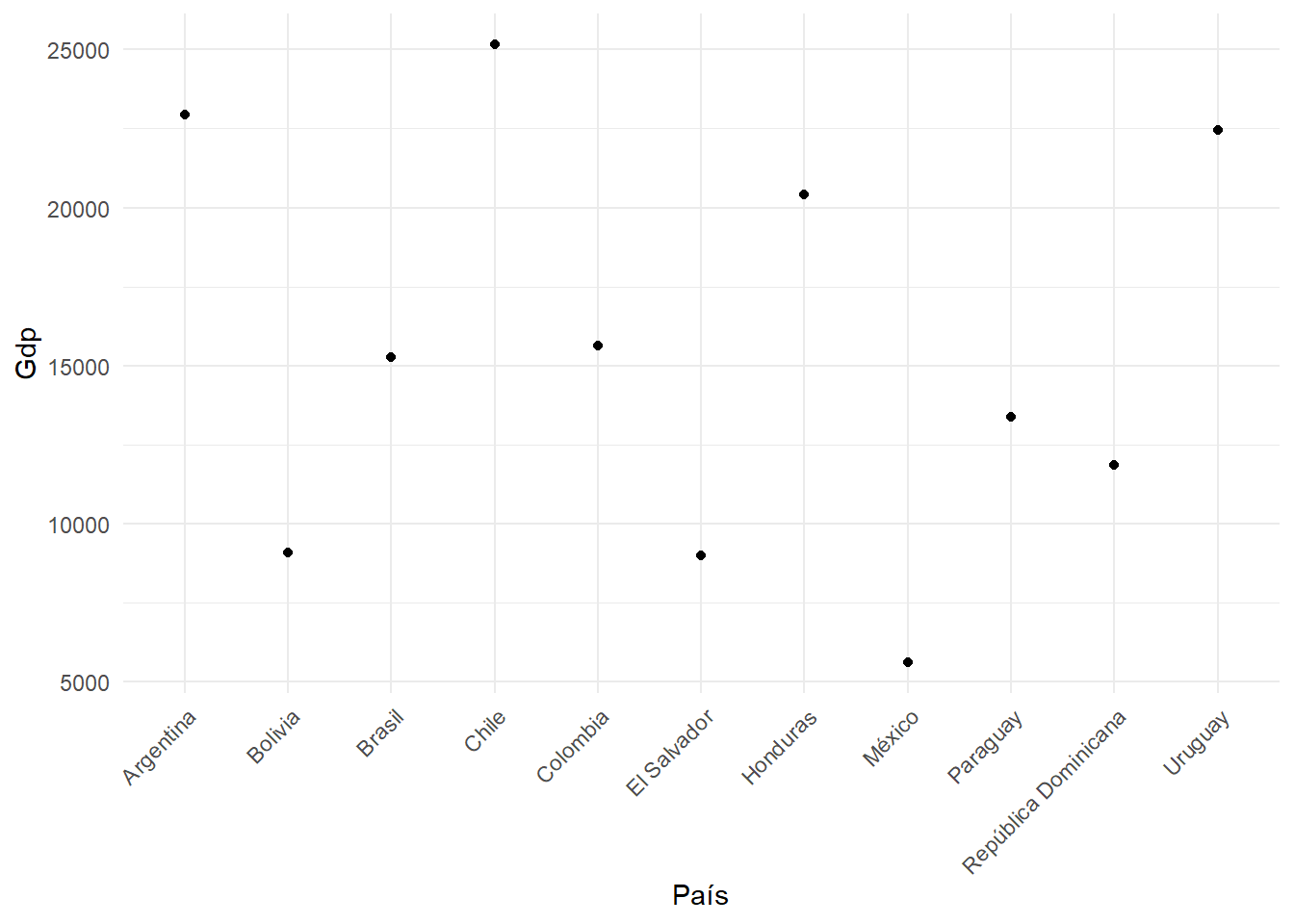
#| fig-cap: "Producto interno bruto por país"
ggplot(data, aes(x = idenpa, y = gdp)) +
geom_point() +
labs(x = "País", y = "Gdp") +
theme_minimal()+
theme(axis.text.x = element_text(angle = 45, hjust = 1))
```
Sin embargo la @fig-gdp entrega información desordenada. Mejor ordenar por tamaño de PIB que por orden alfabético de los países. Para eso
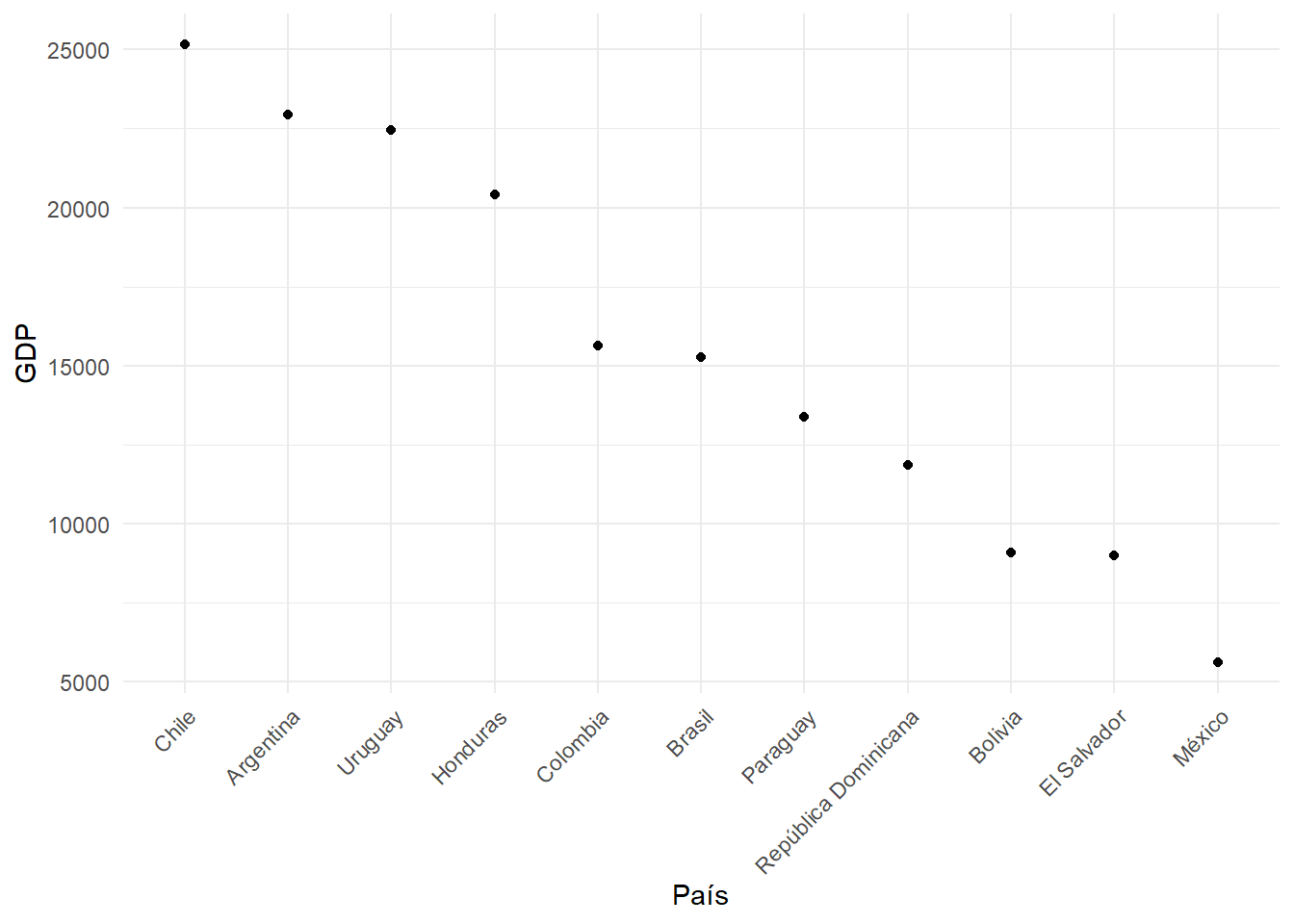
```{r}
#| label: fig-gdp-order
#| fig-cap: "Producto interno bruto por país ordenado"
data_sorted <- data %>% arrange(desc(gdp))
ggplot(data_sorted, aes(x = factor(idenpa, levels = idenpa), y = gdp)) +
geom_point() +
labs(x = "País", y = "GDP") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
```
Ahora sí la @fig-gdp-order muestra un gráfico más ordenado.
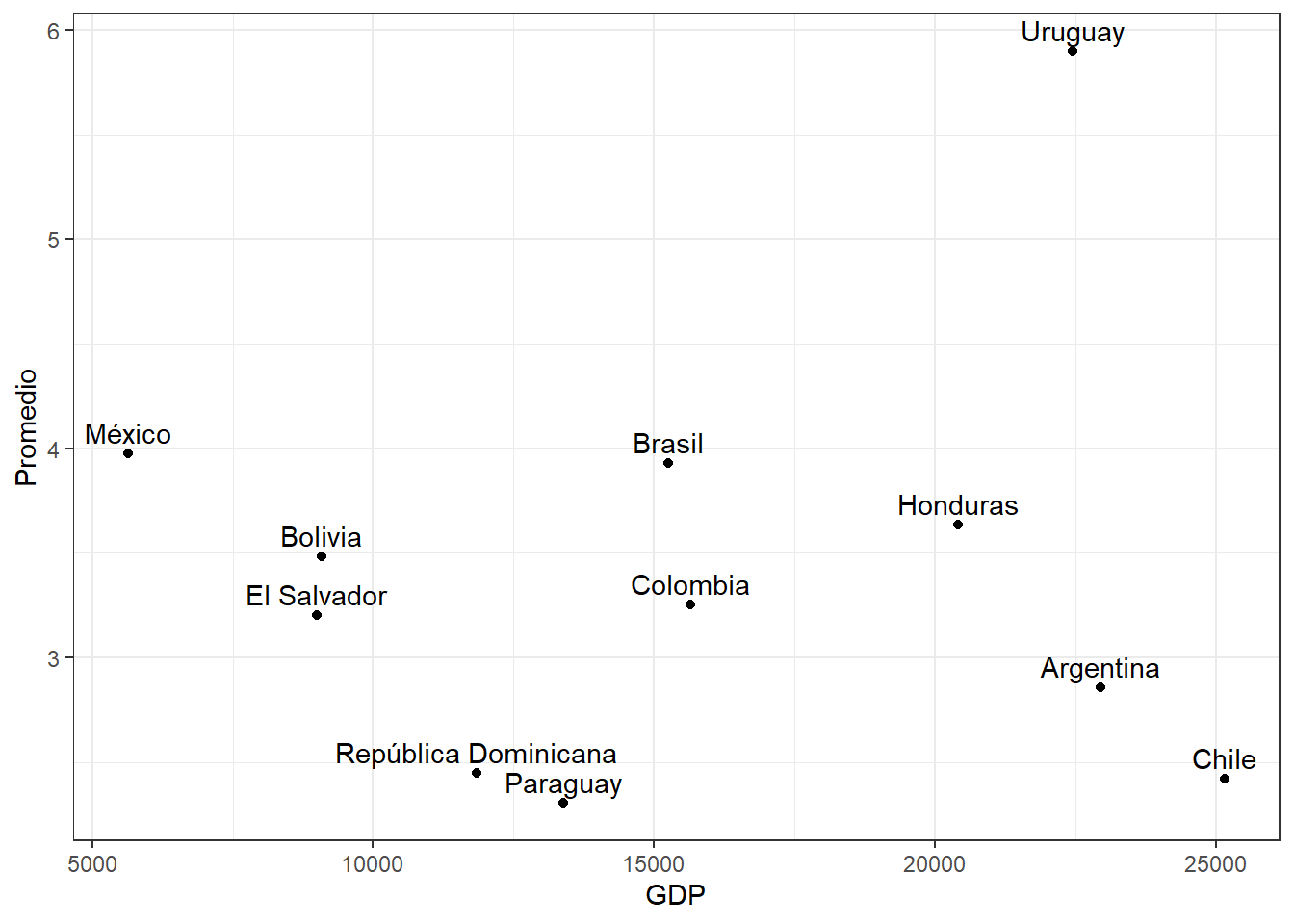
Y comparar el promedio de confianza en instituciones según producto interno bruto por país?
```{r}
#| label: fig-ctr
#| fig-cap: "Confianza en instituciones según el producto interno bruto por país"
data %>%
ggplot(aes(x = gdp, y = promedio, label = idenpa)) +
geom_point() +
geom_text(vjust = -0.5) +
labs(x = "GDP", y = "Promedio") +
theme_bw()
```
La @fig-ctr muestra la relación que existe entre el producto interno bruto y la confianza en instituciones para los 18 países analizados. Es interesante comparar los casos de Chile y urugay, que al tener similar GDP, tienen un nivel de confianza en instituciones muy diferente.